Kafka and the Enterprise Knowledge Graph
The Enterprise Knowledge Graph
First up, what’s a knowledge graph? Read this.
In the article, Jo cribs a line from Google’s announcement of their Knowledge Graph product, which I’m going to reproduce here:
“we’ve been working on an intelligent model — in geek-speak, a ‘graph’ — that understands real-world entities and their relationships to one another: things, not strings.”
This should sound familiar to linked data geeks.
Want a decent argument for why it’s important? Here you go.
Obviously I’m prejudiced, having worked in the graph and linked-data world for a number of years. To me, reifying and mapping out your data domain and its entities in a graph shape is logical, and using triple-stores is a good way of enforcing global uniqueness.
That said, I’d probably pragmatically opt for something like Neo4j in practice rather than going for a RDF triple store, as I’ve had too much pain with performance and maintenance of those technologies over the years.
Fundamentally, we need an ontology or vocabulary for our organisation that’s agreed upon, understood and available.
Jo succinctly puts it:
A knowledge graph acquires and integrates information into an ontology and applies a reasoner to derive new knowledge.
In case you’re curious about linked data, here’s a great post by my old boss… and a slightly more sleep deprived one.
The EKG and Schema registries
At the Kafka Summit yesterday, one of the most interesting details was that Yelp had implemented a schema registry of their own for their Kafka platform. This is because, at the time, the Confluent schema registry did not exist.
They hide Kafka behind their registry and require both consumers and producers to register the schema entities they want to log with the central schema registry before they can access the Kafka topic they need.
As they use the AVRO format, schema evolution and compression is handled in quite a slick manner, but they also did caution that it imposes an overhead in languages like python, where the tooling around the format is more immature.
Choosing JSON in this situation would be possible, but would mean more engineering effort (or metadata in the registration process) in order to handle up- or down- versioning of entities.
I’m not sure I’d go so far as to stop access without registration, but providing a standard library for producers and consumers that closes over the registration abstraction when initializing is probably a pragmatic middle ground, but to be honest I haven’t totally decided yet where I fall on that question.
In this manner, they suddenly found themselves with an internal ontology, by accident. Enlisting an intern to help, they built a UI on top, called Watson.
Under the hood, it’s a MySQL database. I asked in the Q&A if they had ever considered a graph-based modelling strategy or graph data store.
They said that if they had had the expertise at the time, that’s probably an avenue they would have persued, knowing what they do now.
Essentially, as a side-effect of streaming, log-based integration patterns, we can end up with an enforceable and machine-queryable EKG, backed by a graph that models our domain. This is pretty exciting.
Architecture
Although obviously using a streaming or log-based integration strategy implies that all data flows will be two-way, for now, let’s draw this out as a classic one-way ETL-type pipeline.
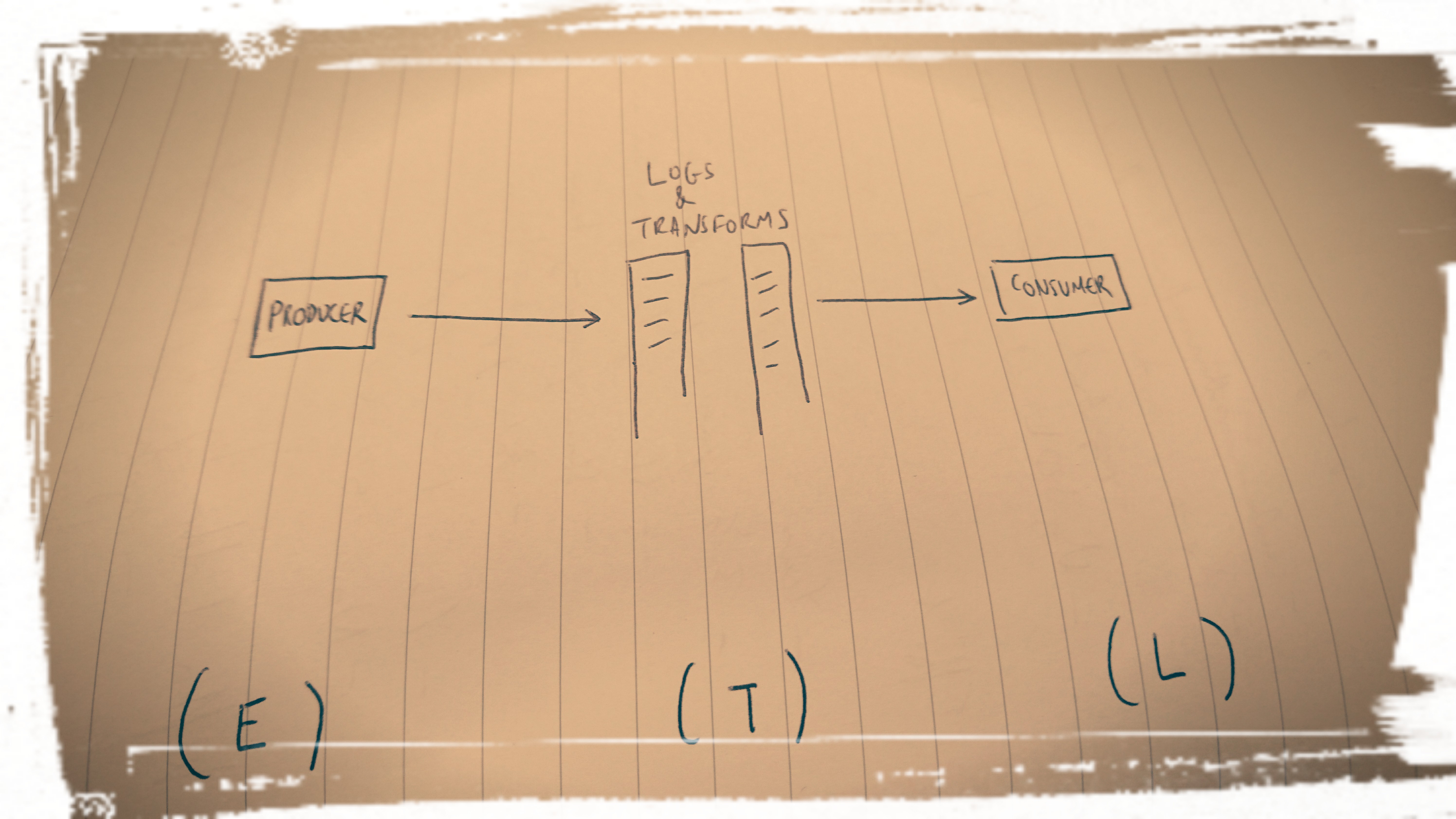
Now let’s add in the EKG.
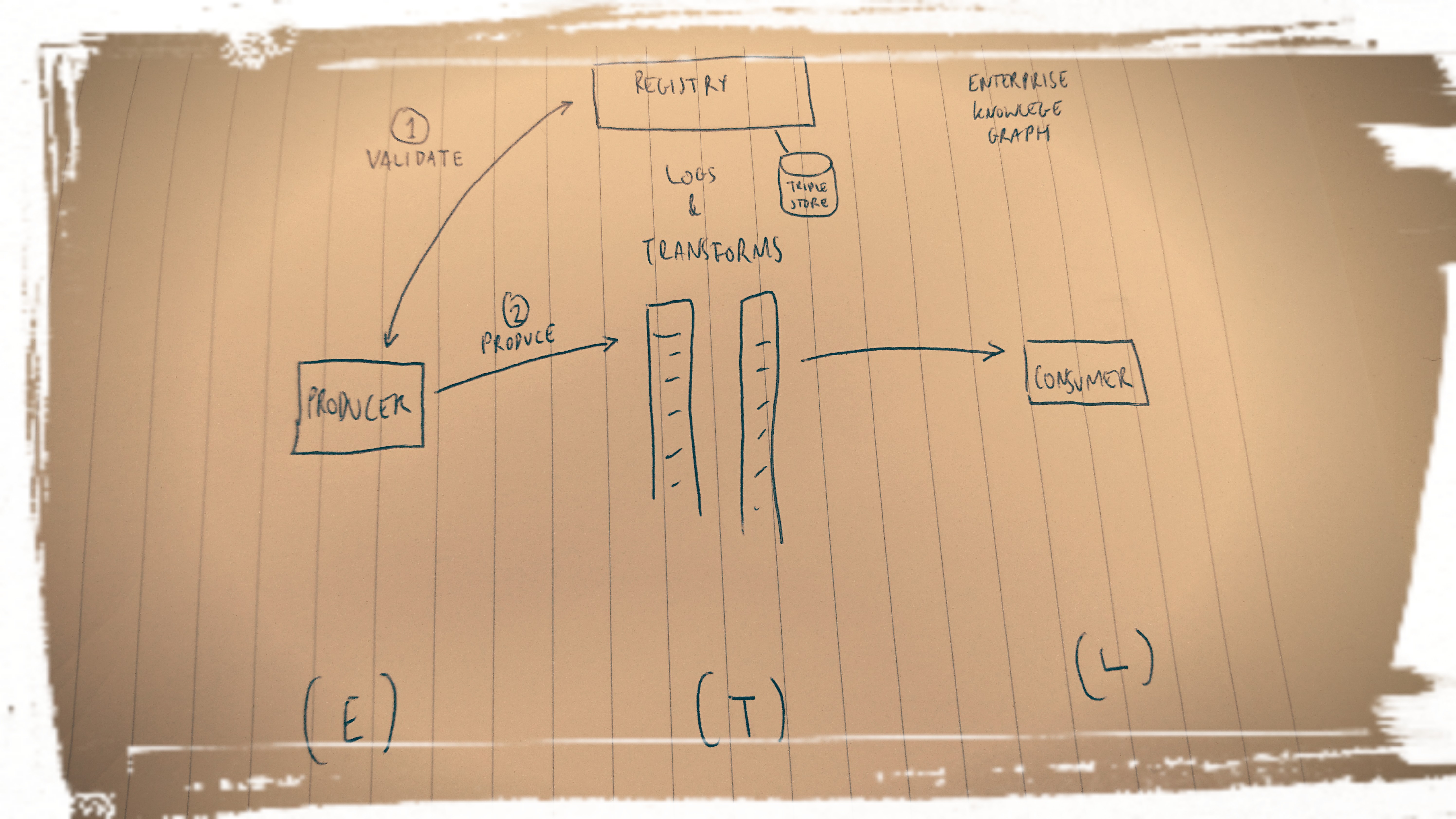
I’m pretty sure this passes the Rich Hickey simplicity test - “Simple is objective.”
In practice it might be a little less so, but hey:
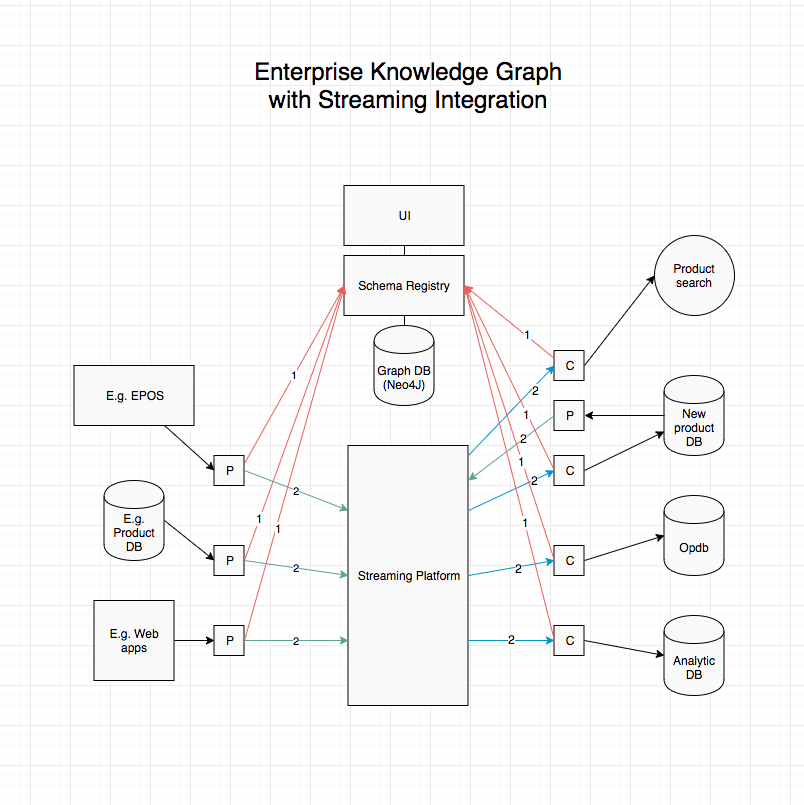
I think this is pretty cool, but maybe that’s just me.
Alex Lynham
Notes on working for a startup in Manchester and various other projects.
alex@lynh.am

